M.S. in Artificial Intelligence ('26) · University of Michigan
Interested in what signals encode about the physical world and how to build models that learn that structure robustly.
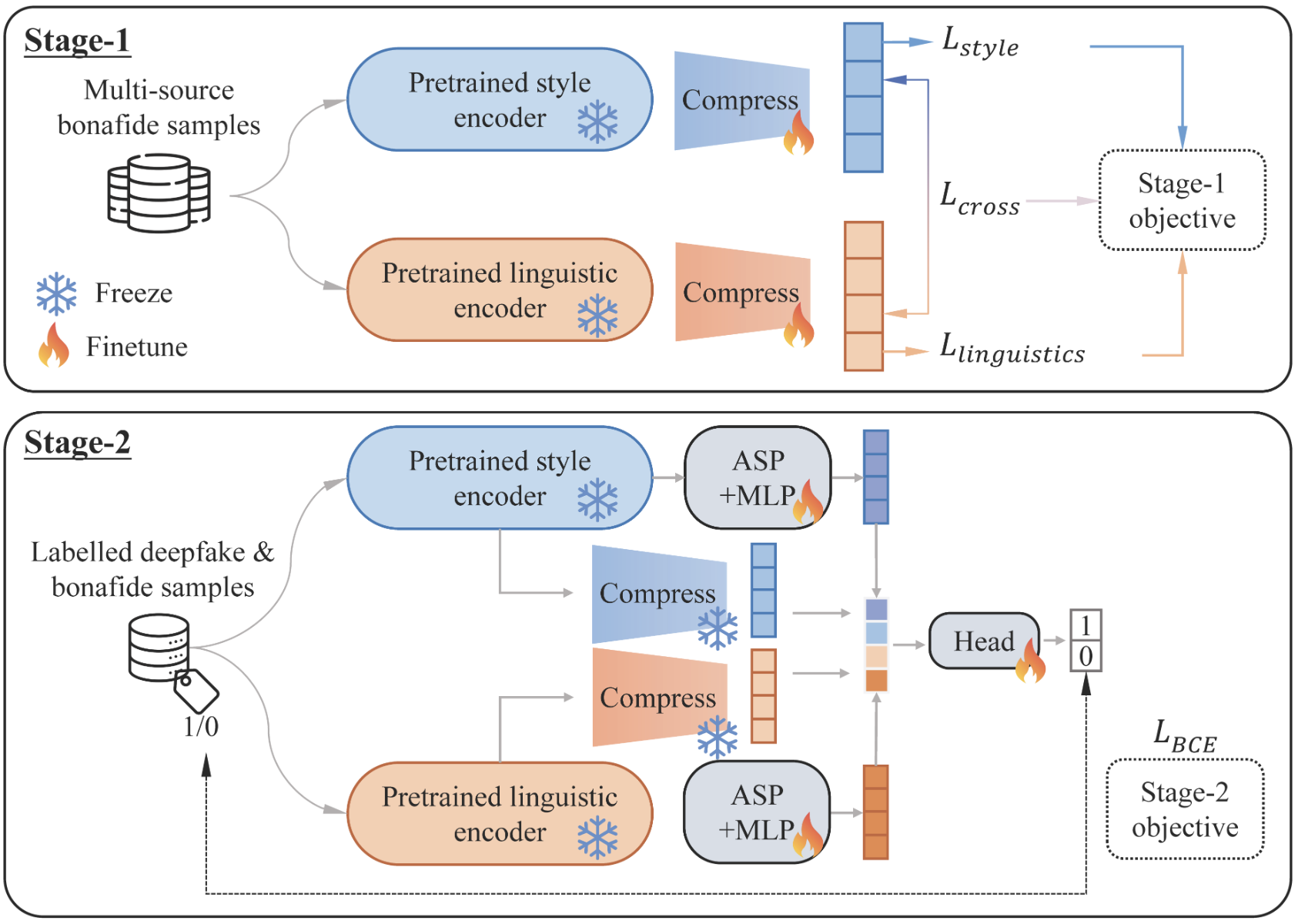
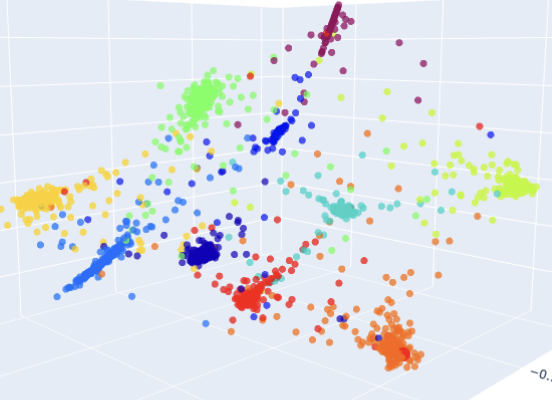
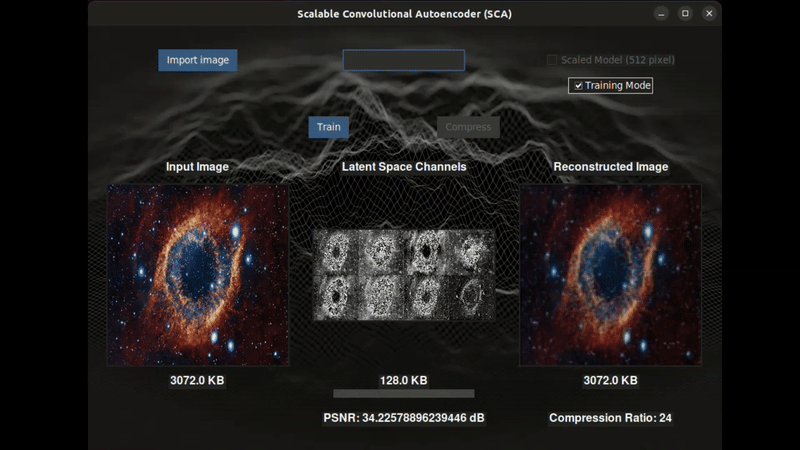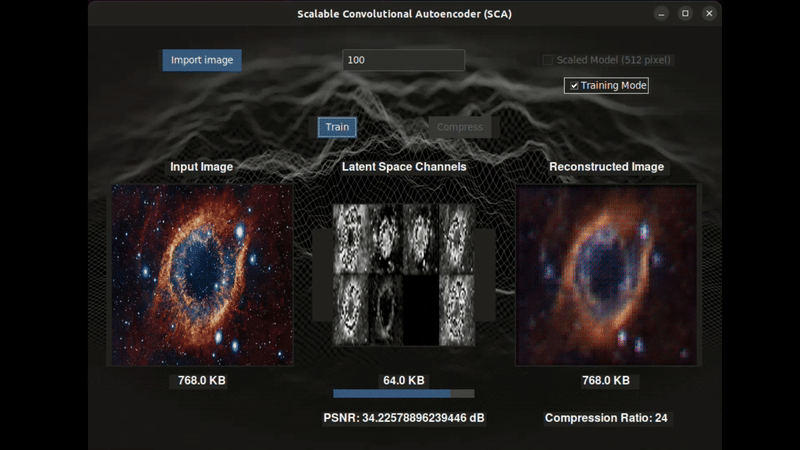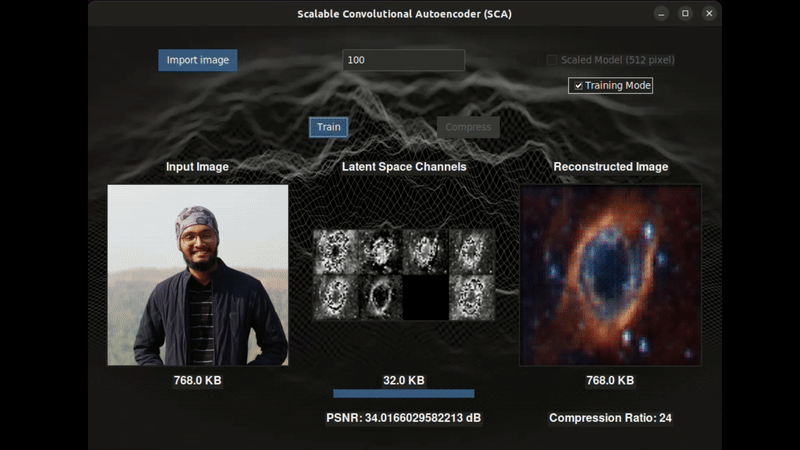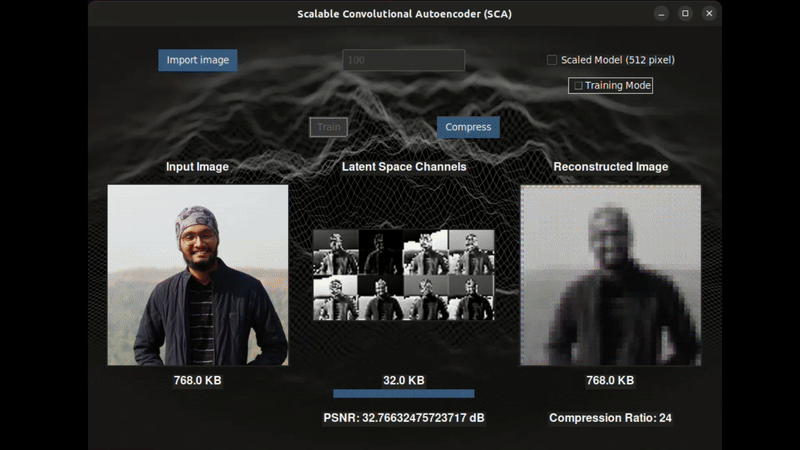
MS in AI from the University of Michigan, researching audio deepfake detection at the ISSF Lab under Prof. Hafiz Malik. My work focuses on the latent representations of speech produced by SSL models: how similarity function choice and negative scaling shape the geometry of those representations, and what that geometry reveals about the boundary between real and synthetic voice. I use supervised contrastive learning to reshape the embedding space of large speech encoders (XLS-R, WavLM, HuBERT) for deepfake detection, and I am interested in what different layers encode about the physical structure of speech.
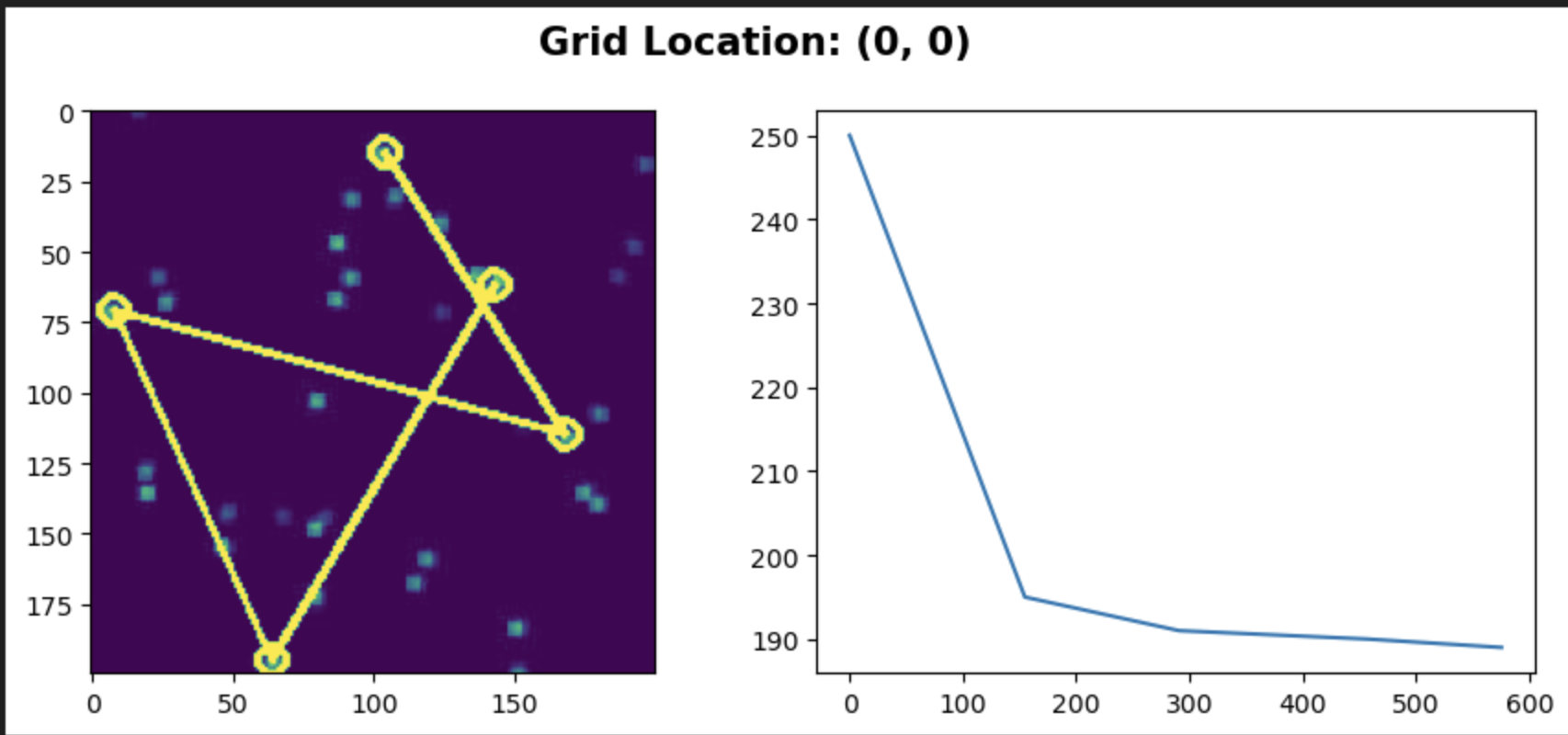
My background spans representation learning, contrastive and self-supervised methods, and signal processing. On the computer vision side, I have worked on semantic segmentation, behavioral cloning agents, and Siamese networks.